I'm so excited that following about seven months of work "skimr" an R package for summarizing data has been released! It's based on idea from Amelia McNamara for a "frictionless, pipeable approach to dealing with summary statistics." Like me, Amelia teaches introductory statistics to undergraduates, and I could immediately see where she was going with the idea for both students and researchers.
The thing that excites people the most about skimr is when they see the inline histograms (aka spark graphs) which is definitely cool. In fact it was so exciting that even Edward Tufte tweeted about it a few times, first because he liked the spark graphs, then because he didn't like how we were handling (actually not handling) decimals. As Michael Quinn tweeted: "Omg. Omg. Omg. Ed Tufte made fun of me on Twitter. Life complete." As you can see below the whole thing worked out and we're not showing 9 decimals any more (unless you change the formats).
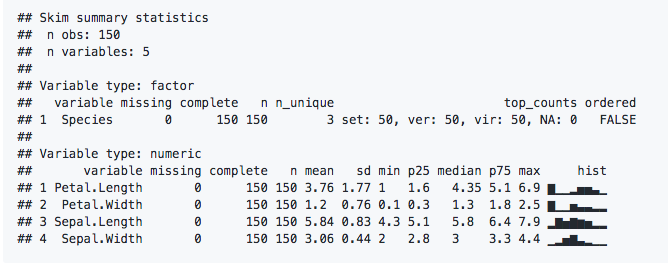
Amazingly the first StackOverflow question about skimr was posted on May 30, and it's been kind of a wild ride ever since, with over 300 stars and a steady but not overwhelming stream of issues and pull requests.
So, how did this happen?
Last Spring I saw a tweet about the ROpenSci Unconference and how great it was. I had been paying attention to the ROpenSci project on and off for a while, but it always had seemed not to have much in the way of social science. However, this time when I looked at the site it was a lot bigger and broader and even had a history package. So I took a deep breath and filled out the application saying something like "you don't have any sociologists, and you should." I had no idea what the chances were but next thing I knew I was talking with their excellent community manager Stefanie Butland in a pre unconf interview.
One of the cool and somewhat intimidating things about ROpenSci is that even though I had met essentially no one before (ok I saw Hadley give a talk once), I knew people from using their packages and #rstats on Twitter. Still it was intimidating, first of all, lots of people with packages, Ph.D.s in statistics, and all kinds of really amazing science work. I was especialy excited that Sean Kross was going to be there since I use his Swirl package constantly in my class, and we'd emailed back and forth some.
The unconference was really amazing, and unlike anything I've attended. People have already blogged about the process elsewhere, but essentially by lunch on day one we had broken up into self-organized groups of different sizes (from 1 to maybe 8) and were working on projects. And then, more or less people worked on those projects (though some individuals switched up or finished their first projects quickly) for the rest of the time through to the presentation at the end. So it was kind of like a hackathon, but with better food, no prizes, not staying up all night and almost everyone with a Ph.D. or in a doctoral program. And lots of women. So, not really like a hackathon.
I've been on kind of an extended vacation from group coding for a couple of years, but it really brought back for me how much fun it can be to be white boarding and coding with others, especially when the group is positive and open. Okay, I'm just going to say it, it's the first time I've ever really worked on code in a group that was half women and that was just amazing, especially when reflecting afterwards on what made it so different from past experiences. But more about that another time.
People in our group came with wildly different backgrounds, and I feel everyone was trying and learning new things. For example, a lot of us learned a lot more about unit testing in R and particularly using the testthat package. I feel like I really came to understand S3 methods. Other people learned to think about code style, mastering git, package structure, and how "stats 101 students" think. Over the two days we moved pretty quickly from prototype to a fairly polished first version. For me it was great to be using the muscles you need for a public facing project again, and how that creates a different kind of code practice and attention to detail and the big picture.
I really like skimr and it clearly was of interest, so I kept working on it as did Michael Quinn. Over the summer and fall we did some refactoring and ironed out some issues, wrote up vignettes, got to 100% test coverage and overall continued to make good progress on it. A few weeks ago we realized that we had just a few things to do before we were ready to give CRAN a try. We got those done, and here we are. There is still at least one outstanding item, which is coming up with a reasonable approach to rendering the spark graphs on Windows. Still, here we are.
I've been saying to various people for the past couple of weeks "you know it changes when you have users" and that is definitely true. I do feel like I see a fairly high abandonment rate of R packages especially when they are Github only. But I also feel like we're ready and we have a good idea of what is in and out of scope for this project. Also the #rstats community and definitely the community of people doing science with R are really great. So I'm committed to being a good CRAN project maintainer.
- Written by: Elin Waring
I've been wanting to post about my experiences teaching using R and RStudioServer for teaching. I've got a list of big picture things, but today I'm thinking about a small, but for me crucial, one.
In my classes and workshops I often use an rmarkdown template to help students get started. You get the option to use a template when you create a new rmarkdown file. Rmarkdown comes with two default templates one for a github document and one for a package vignette. Both are wordy, but less so than the default markdown file, which my students find confusing at first and the annoying in always having to blank out.
From the user point of view, a template is an RMarkdown file which contains some amount of predefined structure. I made that intentionally vauge because you can have a template that is a blank file if you want. But more often in my teaching I use templates to scaffold student work as they are learning to use R and RMarkdown. Scaffolding is a term used in writing pedagogy. Around Lehman most of the time it is used to me giving a students a process of brainstorming, drafting, revision and polishing (and more depending on the course). It is also used to mean providing students with a structure for getting from point A to point B. In my case point B is understanding specific concepts in statistics and R.
I use templates for both of these kinds of scaffolding when I teach with R. For example, in the early exposure to R the experience can be very overwhelming for students. With a template I can structure experiences that are simple, but highly rewarding. For example, they might just have to add a title to a graph, enter variable names into an analysis, and write some text. For students who are further along, a template might provide the outline for a research report. I also have a blank template that gets around the "first delete everything but the stuff at the top" step.
Creating a template is easy. It is just a markdown file. For example this is a somewhat complex file I created for a two-hour introduction to data science workshop this summer. The students had never used R before nor had most of them had any sociology, so I wanted to make a structure for the online part of the workshop that would ensure success. This is the almost blank template file that I'm considering making even more blank. This is an outline for a project report.
You could, of course, just share these as gists, but I like to put them into a package so they can be opened directly from RStudio. To do that you can include them in an R package. Loading the package will add them to the list of options when creating a new file. if you don't have a package you can use any of the package making tools to create a skeleton package.
The templates rely on the somewhat magical inst folder in R packages. That directory holds "installed files" which are basically all the other files you might need in your package. They get copied to the top level when your package is installed using whatever file structure you have given them.
These templates always require two files, and they go into a subfolder in the inst/rmarkdown/templates folder. So the blank template would be in inst/rmarkdown/templates/blank. At that level you add a file called template.yaml. It is extremely important that you make sure there is an a in the yaml file extension or RStudio willl not recognize that file when it scans for templates to list. Be careful because in saving and copying RStudio defaults to yml.
The templates.yaml file should contain two items, name: and description.
name: blank
description: >
A blank template
The other file should be called skeleton.Rmd and placed in a subfolder called skeleton.
The biggest problems I have with this system have to do with file extensions. If you have yml instead of yaml or rmd instead of Rmd the templates may not show up on the list of templates. The case issue is (from what I can tell) specific to Linux which is what most people probably have their instances of RStudioServer installed on.
Another small issue is that different operating systems sort alphabetically differently, so not all students see the same list in the same order.
Also I want to note that there is a whole different category of things called templates that are related to the templates package. It's not the only time that the same term is used in the context of unrelated things in R.
Updated to add information about the Rmd file extension.
- Written by: Elin Waring
In 1939 Edwin Sutherland gave a presidential address to the American Sociological Society, and it made page 12 of the New York Times. Nine full paragraphs summarized his talk, reporting that "Dr. Sutherland described present day white collar criminals as 'more suave and deceptive' than last century's 'robber barons' and asserted that 'in many periods more important crime news may be found on the financial pages of the newspapers than the front pages.'"
That speech, on December 27, is usually considered the moment at which the term "white collar crime" was invented. Of course crimes by elites, crimes of deception, financial crimes, and crimes in business had been written about at least since Leviticus, Sutherland pulled all these concepts together with one incredibly evocative phrase. I've often wondered if this story was really as clear cut as the story makes out. I took a look at the Google books n-gram data for "white collar crime" and "white-collar crime" (full size graph).
"White Collar Crime" Usage Over Time, 1920-2008
The n-gram data certainly seems to be consistent with the story. The data are far from perfect (we know Google scanned a lot of books but not how they chose them; it seems certain that it was not random; also sometimes they include modern additions or annoations) but the data are always interesting to consider.
I also was curious about whether the term white-collar crime displaced anything else but that seems not to have been the case, at least in any obvious way. Still, it is interesting to see the rise of the term "financial crime" since the mid-1970. The persistence of "robber barons" (with its own history) is also fascinating since it is also such an evocative term. (full size graph)
Use of Five Related Terms, 1920-2008
Sutherland's book White Collar Crime was published in 1948 and it is probably fair to attribute to it what is essentially a doubling of the use of the term (if you combine uses with and without the hyphen) at that point. But even before then his work shook things up in the world of sociology and particularly the sociological study of crime. I've written before about how Robert Merton revised his "Social Structure and Anomie" paper in response to Sutherland, and how that revision made the version that appeared in Social Theory and Social Structure so much more powerful. The fact that criminology students are often assigned the 1938 version is maddening to me.
I am really interested in the peak that happened in 1980, which is right around the time that all the federal money that paid part of my way through graduate school and funding the work that led to Crimes of the Middle Classes was awarded. That is around the same time as the Conyers report and the founding of the National White Collar Crime Center.
Overall, at least for now, it seems as though the story of Sutherland's invention of white collar crime as both a phrase and a form of classification seems to be true.
- Written by: Elin Waring